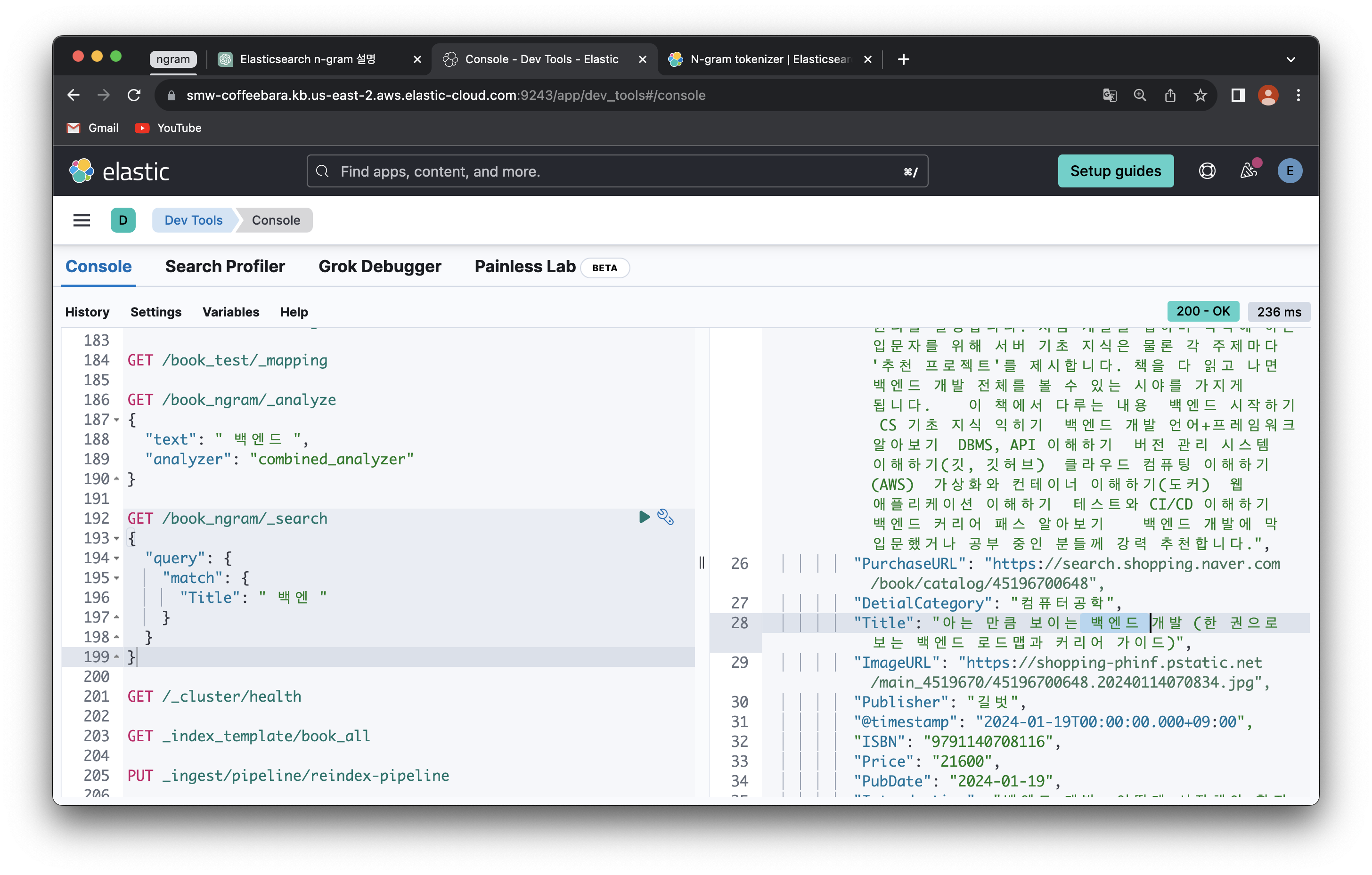


dev tools로 잘 된다
문제가 뭐 였냐면 띄어쓰기 문제였음
저 "text"랑 "Title" 검색할 때 공백이 있어야... ngram 으로 나누어 지던디...
PUT /book_ngram
{
"settings": {
"analysis": {
"tokenizer": {
"my_tokenizer": {
"type": "ngram",
"min_gram": 3,
"max_gram": 3
}
},
"analyzer": {
"combined_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer"
}
}
}
},
"mappings": {
"properties": {
"Title": {
"type": "text",
"analyzer": "combined_analyzer"
},
"PublisherReview": {
"type": "text",
"analyzer": "combined_analyzer"
}
}
}
}이걸로 하면
공백 없어도 한글 검색되는데,
그러면 영어가 안된다!!!!
AW 만해도 AWS 들어가는 게 나오지 않음
# search_app/search_indexes.py
from django_elasticsearch_dsl import Document, Index
from elasticsearch_dsl import analyzer, tokenizer
from .models import Book
# Elasticsearch DSL을 사용하여 인덱스 정의
book_ngram = Index('book_ngram')
# 분석기 선택 함수
def combined_analyzer(language):
if language == 'english':
return analyzer(analyzer=combined_analyzer, tokenizer=tokenizer('ngram', 'nGram', min_gram=2, max_gram=20), filter=['lowercase'])
elif language == 'korean':
return analyzer('korean_analyzer', tokenizer='nori_tokenizer', filter=['ngram_filter'])
# 모델과 연결
@book_ngram.doc_type
class BookDocument(Document):
class Index:
name = 'book_ngram'
settings = {
'number_of_shards': 1,
'number_of_replicas': 0,
'max_ngram_diff': 20,
'analysis': {
'tokenizer': {
'ngram_tokenizer': {
'type': 'ngram',
'min_gram': 2,
'max_gram': 20
}
},
'analyzer': {
'combined_analyzer': combined_analyzer,
'korean_analyzer': {
'type': 'custom',
'tokenizer': 'nori_tokenizer',
'filter': ['ngram_filter']
}
},
'filter': {
'ngram_filter': {
'type': 'ngram',
'min_gram': 2,
'max_gram': 20
}
}
}
}
class Django:
model = Book
fields = [
'Title',
'PublisherReview'
]
def get_analyzer(self, **kwargs):
# 언어에 따라 분석기 선택
return combined_analyzer(kwargs.get('language', 'english'))VSC 는 이렇게 적용되어 있었고,
PUT /book_ngram
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"max_ngram_diff": 20,
"analysis": {
"tokenizer": {
"ngram_tokenizer": {
"type": "ngram",
"min_gram": 2,
"max_gram": 20
}
},
"analyzer": {
"combined_analyzer": {
"type": "custom",
"tokenizer": "ngram_tokenizer",
"filter": ["lowercase"]
},
"korean_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer",
"filter": ["ngram_filter"]
}
},
"filter": {
"ngram_filter": {
"type": "ngram",
"min_gram": 2,
"max_gram": 20
}
}
}
},
"mappings": {
"properties": {
"Title": {
"type": "text",
"analyzer": "combined_analyzer"
},
"PublisherReview": {
"type": "text",
"analyzer": "combined_analyzer"
}
}
}
}Elasticsearch dev tools에서
세팅 이렇게 넣어주었음
(세팅 넣어줄 때
DELETE book_ngram
index delete 먼저 해주고
위에 세팅 PUT 해주고,
POST _reindex
{
"source": {
"index": "book_test"
},
"dest": {
"index": "book_ngram"
}
}POST reindex 해준 다음에
1. 영어 검색

analyze 결과
분석 나눠서 잘해준다

AW까지만 검색해도 잘 된다
2. 한글

한글도 분석 잘 해준다.

백엔 까지만 해도 백엔드 잘 나온다.
단, 문제가 있다면
한 글자만 검색하는 경우에는
앞에 공백이 있어야 된다.

공백 없이 백만 검색한 경우는 결과 안나옴.

공백 넣어줄 경우 백으로 시작하는 단어가 들어가는 애들 나옴.
수정 >> min_gram 을 1로 바꿔줬더니
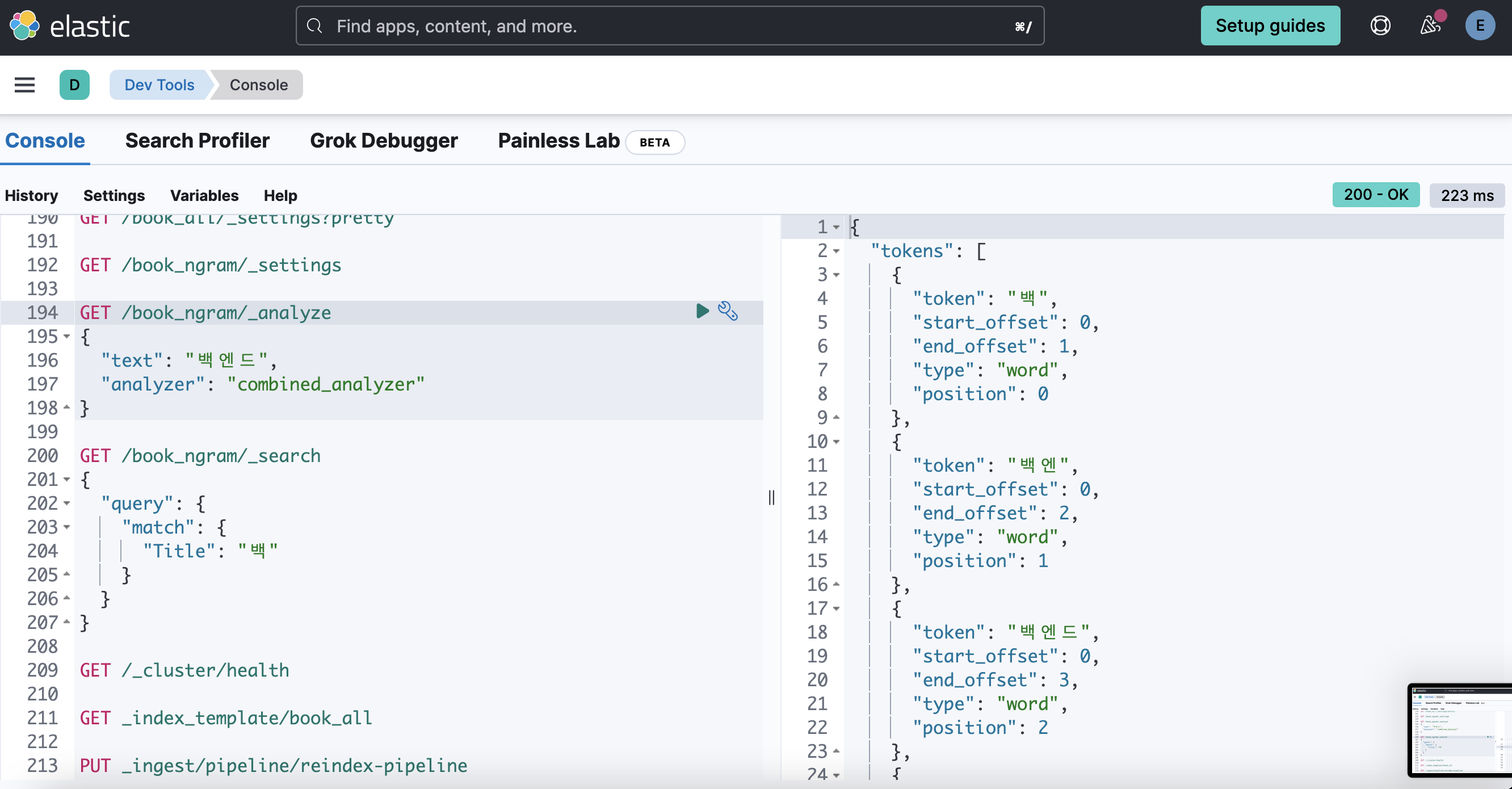

analyze할 때도 한 글자씩 분석해주고


공백 없이 search 해도 잘 된다!!

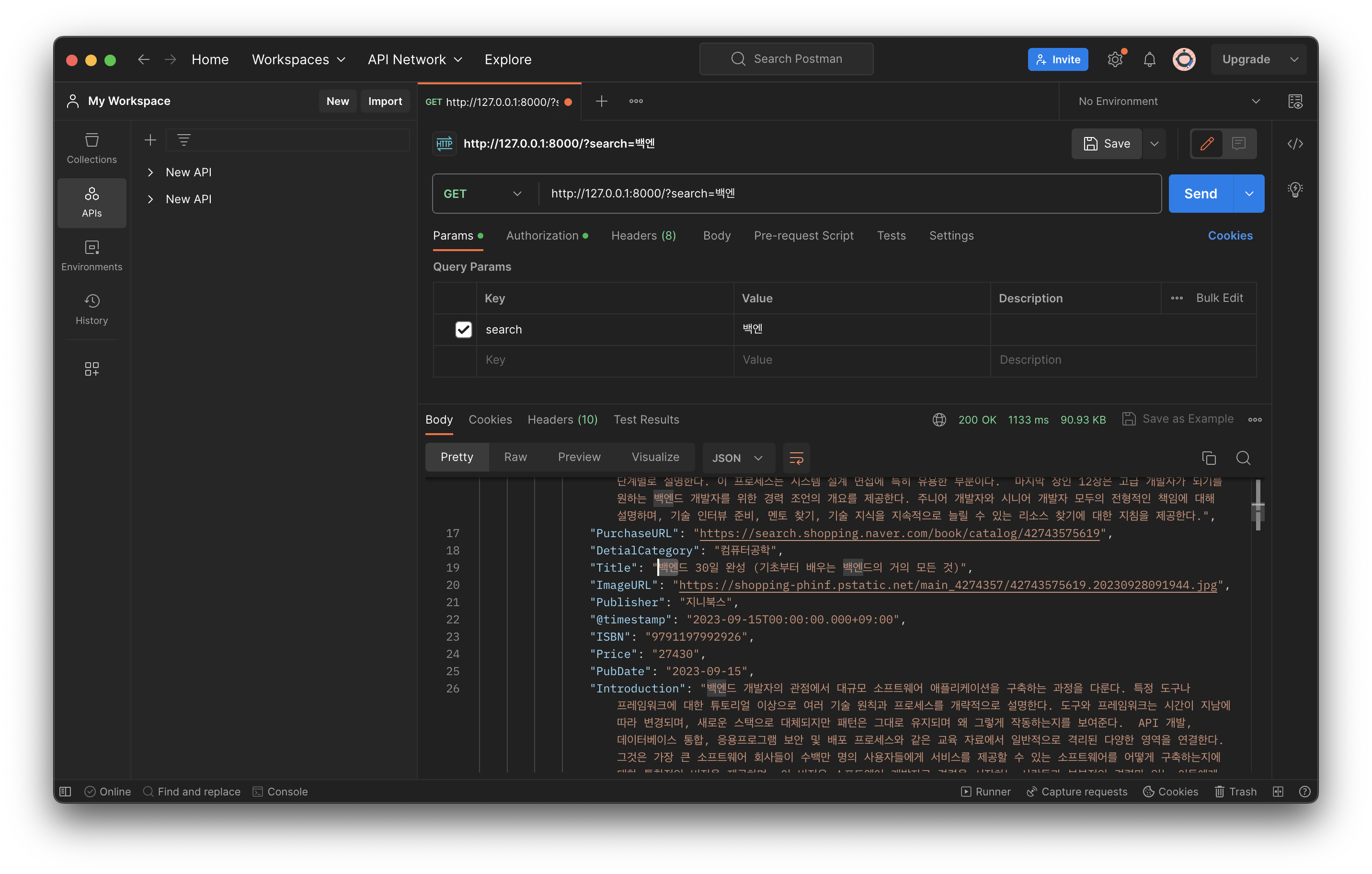

포스트맨이랑 로컬 웹에서도 동일한 결과 확인 완~~~~
이제 git이랑 ecr lambda 에 올리기만 하면 된다 ~~~ 굿굿
'프로젝트 > AWS winter camp - ELK&AWS 프로젝트' 카테고리의 다른 글
| React/js - usenavigate 사용하기 (1) | 2024.02.23 |
|---|---|
| [Figma - 노코드 툴 Anima plugin 연결] npm run dev 에러 해결 (1) | 2024.02.10 |
| Elasticsearch n-gram 적용 / Django 연결 - 1차 수정 (1) | 2024.02.06 |
| Elasticsearch, django - rest_framework로 검색엔진 만들기 - 3차 트러블슈팅(해결) (0) | 2024.02.03 |
| Elasticsearch NLP에 ChatGPT & streamlit에 n-gram 추가하기(실패) (1) | 2024.02.01 |