2/3
# search/views.py
from ast import Match
from django.shortcuts import render
from django.views import View
from django.views.generic import TemplateView
from rest_framework import generics
from elasticsearch_dsl import Search, Q
from .serializers import BookSerializer
import sys
from os.path import abspath, dirname
# 현재 파일의 경로를 통해 프로젝트 루트 디렉토리를 찾음
PROJECT_ROOT = dirname(dirname(abspath(__file__)))
sys.path.append(PROJECT_ROOT)
from search.serializers import Book # 수정된 부분: 정확한 상대 경로로 import
class BookSearchView(View):
template_name = 'book_search.html'
def get(self, request, *args, **kwargs):
query = request.GET.get('query', '')
results = Book.objects.filter(title__icontains=query)
return render(request, self.template_name, {'results': results})
class BookSearchAPIView(generics.ListAPIView):
serializer_class = BookSerializer
def get_queryset(self):
q = self.request.query_params.get('q', '')
s = Search(using='elasticsearch_dsl').query(Match(title={'query': q, 'analyzer': 'ngram_analyzer'}))
response = s.execute()
book_ids = [hit.id for hit in response]
return Book.objects.filter(id__in=book_ids)이전에 엉망이었던 코드에서 ngram 써놓은 걸 우선 찾아본다
https://stackoverflow.com/questions/69465770/django-elasticsearch-dsl-partial-matching-using-ngram-analyzer
Django ElasticSearch DSL partial matching using nGram analyzer
I'm quite new to the ElasticSearch topic and I'm trying to implement simple e-commerce search in my Django application using ElasticSearch with library django-elasticsearch-dsl Github repo . The th...
stackoverflow.com
from elasticsearch_dsl import analyzer, tokenizer
autocomplete_analyzer = analyzer('autocomplete_analyzer',
tokenizer=tokenizer('trigram', 'nGram', min_gram=1, max_gram=20),
filter=['lowercase']
)from elasticsearch_dsl import analyzer, tokenizer
@registry.register_document
class CategoryDocument(Document):
#title: fields.TextField(analyzer=autocomplete_analyzer, search_analyzer='standard') # Here I'm trying to use the analyzer specified above <-- This was extremely incorrect, due to the colon in definition, I don't know how I missed it but I did...
title = fields.TextField(required=True, analyzer=autocomplete_analyzer) # This is it....
class Index:
name = 'categories'
settings = {
'number_of_shards': 1,
'number_of_replicas': 0,
'max_ngram_diff': 20 # This seems to be important due to the constraint for max_ngram_diff beeing 1
}
class Django:
model = Category
fields = [
# 'title' <-- Notice, I removed this field, it would be redeclaration error
# In reality here I have more fields
]
#models.py
class Category(models.Model):
title = models.CharField(max_length=150, blank=False)
description = models.CharField(max_length=150, blank=False)
# In reality here I have more fields
def __str__(self):
return self.title
#views.py
class CategoryElasticSearch(ListView):
def get(self, request, lang):
search_term = request.GET.get('search_term', '')
q = Q(
"multi_match",
query=search_term,
fields=[
'title',
# In reality here I have more fields
],
fuzziness='auto',)
search = search.query(q)
# ... etc계속나오는 에러↓
BadRequestError at /
BadRequestError(400, 'search_phase_execution_exception', '[multi_match] analyzer [combined_analyzer] not found')Request Method:Request URL:Django Version:Exception Type:Exception Value:Exception Location:Raised during:Python Executable:Python Version:Python Path:Server time:
| GET |
| http://127.0.0.1:8000/ |
| 5.0.1 |
| BadRequestError |
| /Users/yangdayeon/myvenv/lib/python3.11/site-packages/elasticsearch/_sync/client/_base.py, line 320, in perform_request |
| search_app.views.SearchView |
| /Users/yangdayeon/myvenv/bin/python3 |
| 3.11.1 |
| Sat, 03 Feb 2024 09:46:35 +0000 |
https://github.com/barseghyanartur/django-elasticsearch-dsl-drf/issues/259
How to use ngram in search query param · Issue #259 · barseghyanartur/django-elasticsearch-dsl-drf
Questions I'm trying to add ngrams to one of my fields title to use directly in the search query param. I would like to be able to find objects even by part of my name. I tried examples on the repo...
github.com
ElasticSearch Ngram 활용하여 검색하는 방법
개요 많은 케이스가 있겠지만 보통 검색 용도로 ElasticSearch를 사용하는 것으로 알고 있다. MySQL의 경우 LIKE쿼리를 사용하여 검색을 할 수 있는데, %파이썬% 과 같이 앞뒤로 %를 사용하여 검색하는
hides.kr
https://cfpb.github.io/consumerfinance.gov/page-search/
Page Search - consumerfinance.gov
Page Search For page searches on consumerfinance.gov, we use Elasticsearch and the django-opensearch-dsl library, which is a lightweight wrapper around opensearch-dsl-py. Indexing For any of our Django apps that need to implement search for their Django mo
cfpb.github.io
수정전 일반 nori_analyzer 만 적용한 검색엔진 코드들 일부
# search_app/views.py
from django.views.decorators.csrf import csrf_exempt
from django.utils.decorators import method_decorator
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import status
from rest_framework.authentication import BasicAuthentication, SessionAuthentication
from rest_framework.permissions import IsAuthenticated
from elasticsearch import Elasticsearch
from .search_indexes import * # Elasticsearch DSL이 정의된 인덱스 import
@method_decorator(csrf_exempt,name='dispatch')
class SearchView(APIView):
authentication_classes = [BasicAuthentication, SessionAuthentication]
permission_classes = [IsAuthenticated]
def get(self, request):
es = Elasticsearch(
cloud_id = 'cloudid',
api_key = 'apikey',
request_timeout=600
)
# 검색어
search_word = request.query_params.get('search', '주식') #기본 검색어 주식으로 설정해서 결과 보는거
if not search_word:
return Response(status=status.HTTP_400_BAD_REQUEST, data={'message': 'search word param is missing'})
docs = es.search(index='book_all',
body={
"query": {
"multi_match": {
"query": search_word,
"fields": ["Title", "PublisherReview"]
}
}
})
data_list = docs['hits']
return Response(data_list)#search_app/models.py
from django.db import models
class Book(models.Model):
title = models.CharField(max_length=255)
author = models.CharField(max_length=255)
def __str__(self):
return self.title# search_app/setting_bulk.py
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.indices.create(
index='dictionary',
body={
"settings": { #ngram tokenizer 추가하기
"index": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer"
}
}
}
}
},
"mappings": {
"dictionary_datas": { #book_all 로 수정
"properties": {
"id": {
"type": "long"
},
"title": {
"type": "text",
"analyzer": "my_analyzer"
},
"content": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
}
)
import json
with open("dictionary.json", encoding='utf-8') as json_file:
json_data = json.loads(json_file.read())
body = ""
for i in json_data:
body = body + json.dumps({"index": {"_index":"dictionary", "_type": "dictionary_datas"}}) + "\n"
body = body + json.dumps(i, ensure_ascii=False) + '\n'
es.bulk(body)이 setting_bulk 이렇게 세팅 매핑 해놓았는데 view에서 애초에 dictionary를 안쓰고 es에 업로드 되어 있는 book_all 데이터로 해서 이게 적용이 안되는 것 같은 ...
그리고 일단
ngram을 적용할 때 내가 nori를 적용을 해놓아서
영어는 ngram이 적용이 안돼서 영어는 standard로 해놔야돼서
둘이 합친 combined_analyzer를 붙이는걸로 했다.
# search_app/search_indexes.py
from django_elasticsearch_dsl import Document, fields, Index
from .models import Book
# Elasticsearch DSL을 사용하여 인덱스 정의
book_index = Index('book_index')
# 모델과 연결
@book_index.doc_type
class BookDocument(Document):
title = fields.TextField()
author = fields.TextField()
class Django:
model = Book
# search_app/setting_bulk.py
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.indices.create(
index='dictionary',
body={
"settings": {
"analysis": {
"analyzer": {
"ngram_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["lowercase", "edge_ngram"]
}
},
"filter": {
"edge_ngram": {
"type": "edge_ngram",
"min_gram": 2,
"max_gram": 20
}
}
}
},
"mappings": {
"dictionary_datas": {
"properties": {
"id": {
"type": "long"
},
"title": {
"type": "text",
"analyzer": "ngram_analyzer"
},
"content": {
"type": "text",
"analyzer": "ngram_analyzer"
}
}
}
}
}
)# search_app/setting_bulk.py
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.indices.create(
index='dictionary',
body={
"settings": {
"analysis": {
"analyzer": {
"ngram_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["lowercase", "ngram_filter"]
}
},
"filter": {
"ngram_filter": {
"type": "edge_ngram",
"min_gram": 2,
"max_gram": 20
}
}
}
},
"mappings": {
"dictionary_datas": {
"properties": {
"id": {
"type": "long"
},
"title": {
"type": "text",
"analyzer": "ngram_analyzer"
},
"content": {
"type": "text",
"analyzer": "ngram_analyzer"
}
}
}
}
}
)# search_app/setting_bulk.py
import json
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.indices.create(
index='book_all',
body={
"settings": {
"analysis": {
"tokenizer": {
"ngram_tokenizer": {
"type": "ngram",
"min_gram": 2,
"max_gram": 20
}
},
"analyzer": {
"combined_analyzer": {
"type": "custom",
"tokenizer": "ngram_tokenizer"
}
}
}
},
"mappings": {
"properties": {
"Title": {
"type": "text",
"analyzer": "combined_analyzer"
},
"PublisherReview": {
"type": "text",
"analyzer": "combined_analyzer"
}
}
}
}
)얘는 create 하는거라서 지우고 다시 매핑세팅을 하라고 한다
지우는 건 위험하기에
파이프라인을 구축하고 reindexing 하는 방법을 시도
근데 챗지피티랑 소통하면서 코드 수정하다가 nori를 잃어버림
수면부족 코딩의 위험성
## search_app/apps.py
from django.apps import AppConfig
class SearchAppConfig(AppConfig):
default_auto_field = 'django.db.models.BigAutoField'
name = 'search_app'
# search_app/apps.py
from django.apps import AppConfig
from elasticsearch import Elasticsearch
class SearchAppConfig(AppConfig):
default_auto_field = 'django.db.models.BigAutoField'
name = 'search_app'
def ready(self):
# Django 앱이 실행될 때 Elasticsearch에 분석기 추가
es = Elasticsearch()
es.indices.put_settings(
index='book_all',
body={
"settings": {
"analysis": {
"tokenizer": {
"ngram_tokenizer": {
"type": "ngram",
"min_gram": 2,
"max_gram": 20
}
},
"analyzer": {
"combined_analyzer": {
"type": "custom",
"tokenizer": "ngram_tokenizer"
}
}
}
}
}
)이러라는데 ...
이러면 갑자기 또 authentication 문제 발생...
그러므로 다시원상복귀.
[Elasticsearch] BadRequestError: BadRequestError(400, 'search_phase_execution_exception', 'runtime error')
field data type이 잘못 지정된 경우 발생하는 오류
velog.io
elasticsearch.exceptions.RequestError: RequestError(400, 'search_phase_execution_exception', '[match] analyzer [name_phonetic] n
Mapping example- spouseNameQuery = { "match": { "Spouse_Name": { # "query": input_dict['Spouse_Name'], "query": val, "analyzer": "name_phonetic", "prefix_length": 1, "minimum_should_match": "100%" } } } body = {"query": {"bool": Dict_all}, "highlight": { "
discuss.elastic.co
https://github.com/elastic/elasticsearch-dsl-py/issues/741
How to apply custom analyzer for query? · Issue #741 · elastic/elasticsearch-dsl-py
I have customized an analyzer named "my_analyzer", and would like to apply it to query. I'm currently doing it in the following way my_analyzer = analyzer('my_analyzer', tokenizer=tokenizer('trigra...
github.com
BadRequestError(400, 'search_phase_execution_exception', '[multi_match] analyzer [combined_analyzer] not found')이 에러는
custom_analyzer가 index에 적용이 안되는 문제인듯하다
When using an analyzer in a query, it needs to be defined on that index. It looks like in this case it is not so. You need to add it to the index before creating it. If you are using Index objects to manage your indices those have an analyzer method that will allow you to add custom analyzers.
2/5
기존 코드
from elasticsearch import Elasticsearch
es = Elasticsearch() #파라미터 추가
# 'combined_analyzer' 분석기를 Elasticsearch에 추가
es.indices.put_settings(
index='book_all',
body={
"settings": {
"analysis": {
"tokenizer": {
"ngram_tokenizer": {
"type": "ngram",
"min_gram": 2,
"max_gram": 20
}
},
"analyzer": {
"combined_analyzer": {
"type": "custom",
"tokenizer": "ngram_tokenizer"
}
}
}
}
}
)
# 기존 인덱스 다시 열기
es.indices.open(index='book_all')
# 기존 인덱스에 대한 alias 설정
es.indices.update_aliases(
body={
"actions": [
{"add": {"index": "new_book_all", "alias": "my_index_alias"}}
]
}
)
# 리인덱스 파이프라인 생성
es.ingest.put_pipeline(
id='reindex_pipeline',
body={
"description": "Reindexing pipeline with new analyzer",
"processors": [
{
"set": {
"field": "_source",
"value": {
"Title": "{{Title}}",
"PublisherReview": "{{PublisherReview}}"
# Add other fields as needed
}
}
}
]
}
)
# 분석기 정의 및 인덱스 생성
es.indices.create(
index='book_ngram',
body={
"settings": {
"analysis": {
"tokenizer": {
"nori_tokenizer": {
"type": "nori_tokenizer"
}
},
"filter": {
"ngram_filter": {
"type": "ngram",
"min_gram": 2,
"max_gram": 20
}
},
"analyzer": {
"combined_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer",
"filter": ["ngram_filter"]
}
}
}
},
"mappings": {
"properties": {
"Title": {
"type": "text",
"analyzer": "combined_analyzer"
},
"PublisherReview": {
"type": "text",
"analyzer": "combined_analyzer"
}
}
}
}
)
# 리인덱스 파이프라인 실행
es.reindex(
body={
"source": {
"index": "book_all"
},
"dest": {
"index": "book_ngram",
"pipeline": "reindex_pipeline"
}
},
wait_for_completion=True,
request_timeout=300
)
수정
from elasticsearch import Elasticsearch
es = Elasticsearch() #파라미터 추가
# 'combined_analyzer' 분석기를 Elasticsearch에 추가
es.indices.put_settings(
index='book_all',
body={
"settings": {
"analysis": {
"tokenizer": {
"ngram_tokenizer": {
"type": "ngram",
"min_gram": 2,
"max_gram": 20
}
},
"analyzer": {
"combined_analyzer": {
"type": "custom",
"tokenizer": "ngram_tokenizer"
}
}
}
}
}
)
# 리인덱스 파이프라인 생성
es.ingest.put_pipeline(
id='reindex_pipeline',
body={
"description": "Reindexing pipeline with new analyzer",
"processors": [
{
"set": {
"field": "_source",
"value": {
"Title": "{{Title}}",
"PublisherReview": "{{PublisherReview}}"
# Add other fields as needed
}
}
}
]
}
)
# 분석기 정의 및 인덱스 생성
es.indices.create(
index='book_ngram',
body={
"settings": {
"analysis": {
"tokenizer": {
"nori_tokenizer": {
"type": "nori_tokenizer"
}
},
"filter": {
"ngram_filter": {
"type": "ngram",
"min_gram": 2,
"max_gram": 20
}
},
"analyzer": {
"combined_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer",
"filter": ["ngram_filter"]
}
}
}
},
"mappings": {
"properties": {
"Title": {
"type": "text",
"analyzer": "combined_analyzer"
},
"PublisherReview": {
"type": "text",
"analyzer": "combined_analyzer"
}
}
}
}
)
# 리인덱스 파이프라인 실행
es.reindex(
body={
"source": {
"index": "book_all"
},
"dest": {
"index": "book_ngram",
"pipeline": "reindex_pipeline"
}
},
wait_for_completion=True,
request_timeout=300
)#search_app/setting_bulk.py
# 리인덱스 파이프라인 생성
es.ingest.put_pipeline(
id='reindex_pipeline',
body={
"description": "Reindexing pipeline with new analyzer",
"processors": [
{
"set": {
"field": "_source",
"value": {
"Title": "{{Title}}",
"PublisherReview": "{{PublisherReview}}"
# Add other fields as needed
}
}
}
]
}
)#search_app/setting_bulk.py
from elasticsearch import Elasticsearch
es = Elasticsearch() #파라미터 추가
# 'combined_analyzer' 분석기를 Elasticsearch에 추가
es.indices.put_settings(
index='book_ngram',
body={
"settings": {
"analysis": {
"tokenizer": {
"ngram_tokenizer": {
"type": "ngram",
"min_gram": 2,
"max_gram": 20
}
},
"analyzer": {
"combined_analyzer": {
"type": "custom",
"tokenizer": "ngram_tokenizer"
}
}
}
}
}
)
# 리인덱스 파이프라인 생성
es.ingest.put_pipeline(
id='reindex_pipeline',
body={
"description": "Reindexing pipeline with new analyzer",
"processors": [
{
"set": {
"field": "_source",
"value": {
"Title": "{{Title}}",
"PublisherReview": "{{PublisherReview}}"
# Add other fields as needed
}
}
}
]
}
)
# 분석기 정의 및 인덱스 생성
es.indices.create(
index='book_ngram',
body={
"settings": {
"analysis": {
"tokenizer": {
"nori_tokenizer": {
"type": "nori_tokenizer"
}
},
"filter": {
"ngram_filter": {
"type": "ngram",
"min_gram": 2,
"max_gram": 20
}
},
"analyzer": {
"combined_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer",
"filter": ["ngram_filter"]
}
}
}
},
"mappings": {
"properties": {
"Title": {
"type": "text",
"analyzer": "combined_analyzer"
},
"PublisherReview": {
"type": "text",
"analyzer": "combined_analyzer"
}
}
}
}
)
# 리인덱스 파이프라인 실행
es.reindex(
body={
"source": {
"index": "book_all"
},
"dest": {
"index": "book_ngram",
"pipeline": "reindex_pipeline"
}
},
wait_for_completion=True,
request_timeout=300
)# search_app/search_indexes.py
from django_elasticsearch_dsl import Document, fields, Index
from elasticsearch_dsl import analyzer, tokenizer
from .models import Book
# Elasticsearch DSL을 사용하여 인덱스 정의
book_ngram = Index('book_ngram')
combined_analyzer = analyzer('combined_analyzer',
tokenizer=tokenizer('ngram', 'nGram', min_gram=2, max_gram=20),
filter=['lowercase']
)
# 모델과 연결
@book_ngram.doc_type
class BookDocument(Document):
Title = fields.TextField(analyzer='combined_analyzer', search_analyzer='standard')
PublisherReview = fields.TextField(analyzer='combined_analyzer', search_analyzer='standard')
class Index:
name = 'book_ngram'
settings = {
'number_of_shards': 1,
'number_of_replicas': 0,
'max_ngram_diff': 20
}
class Django:
model = Book
fields = [
'Title',
'PublisherReview'
]python3 manage.py runserver
Watching for file changes with StatReloader
Performing system checks...
Exception in thread django-main-thread:
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/threading.py", line 1038, in _bootstrap_inner
self.run()
File "/Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/threading.py", line 975, in run
self._target(*self._args, **self._kwargs)
File "/Users/yangdayeon/myvenv/lib/python3.11/site-packages/django/utils/autoreload.py", line 64, in wrapper
fn(*args, **kwargs)
File "/Users/yangdayeon/myvenv/lib/python3.11/site-packages/django/core/management/commands/runserver.py", line 133, in inner_run
self.check(display_num_errors=True)
File "/Users/yangdayeon/myvenv/lib/python3.11/site-packages/django/core/management/base.py", line 485, in check
all_issues = checks.run_checks(
^^^^^^^^^^^^^^^^^^
File "/Users/yangdayeon/myvenv/lib/python3.11/site-packages/django/core/checks/registry.py", line 88, in run_checks
new_errors = check(app_configs=app_configs, databases=databases)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/yangdayeon/myvenv/lib/python3.11/site-packages/django/core/checks/urls.py", line 14, in check_url_config
return check_resolver(resolver)
^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/yangdayeon/myvenv/lib/python3.11/site-packages/django/core/checks/urls.py", line 24, in check_resolver
return check_method()
^^^^^^^^^^^^^^
File "/Users/yangdayeon/myvenv/lib/python3.11/site-packages/django/urls/resolvers.py", line 516, in check
for pattern in self.url_patterns:
^^^^^^^^^^^^^^^^^
File "/Users/yangdayeon/myvenv/lib/python3.11/site-packages/django/utils/functional.py", line 47, in __get__
res = instance.__dict__[self.name] = self.func(instance)
^^^^^^^^^^^^^^^^^^^
File "/Users/yangdayeon/myvenv/lib/python3.11/site-packages/django/urls/resolvers.py", line 735, in url_patterns
patterns = getattr(self.urlconf_module, "urlpatterns", self.urlconf_module)
^^^^^^^^^^^^^^^^^^^
File "/Users/yangdayeon/myvenv/lib/python3.11/site-packages/django/utils/functional.py", line 47, in __get__
res = instance.__dict__[self.name] = self.func(instance)
^^^^^^^^^^^^^^^^^^^
File "/Users/yangdayeon/myvenv/lib/python3.11/site-packages/django/urls/resolvers.py", line 728, in urlconf_module
return import_module(self.urlconf_name)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<frozen importlib._bootstrap>", line 1206, in _gcd_import
File "<frozen importlib._bootstrap>", line 1178, in _find_and_load
File "<frozen importlib._bootstrap>", line 1149, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 690, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 940, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "/Users/yangdayeon/myvenv/bin/server_project/server_project/urls.py", line 25, in <module>
path('', include('search_app.urls')),
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/yangdayeon/myvenv/lib/python3.11/site-packages/django/urls/conf.py", line 38, in include
urlconf_module = import_module(urlconf_module)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<frozen importlib._bootstrap>", line 1206, in _gcd_import
File "<frozen importlib._bootstrap>", line 1178, in _find_and_load
File "<frozen importlib._bootstrap>", line 1149, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 690, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 940, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "/Users/yangdayeon/myvenv/bin/server_project/search_app/urls.py", line 3, in <module>
from search_app import views
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/yangdayeon/myvenv/bin/server_project/search_app/views.py", line 16, in <module>
from .search_indexes import * # Elasticsearch DSL이 정의된 인덱스 import
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/yangdayeon/myvenv/bin/server_project/search_app/search_indexes.py", line 16, in <module>
@book_ngram.doc_type
^^^^^^^^^^^^^^^^^^^
File "/Users/yangdayeon/myvenv/lib/python3.11/site-packages/django_elasticsearch_dsl/indices.py", line 22, in document
registry.register_document(document)
File "/Users/yangdayeon/myvenv/lib/python3.11/site-packages/django_elasticsearch_dsl/registries.py", line 58, in register_document
raise RedeclaredFieldError(
django_elasticsearch_dsl.exceptions.RedeclaredFieldError: You cannot redeclare the field named 'Title' on BookDocument
^C%
이 에러는
# search_app/search_indexes.py
from django_elasticsearch_dsl import Document, Index
from elasticsearch_dsl import analyzer, tokenizer
from .models import Book
# Elasticsearch DSL을 사용하여 인덱스 정의
book_all = Index('book_all')
combined_analyzer = analyzer('combined_analyzer',
tokenizer=tokenizer('ngram', 'nGram', min_gram=2, max_gram=20),
filter=['lowercase']
)
# 모델과 연결
@book_all.doc_type
class BookDocument(Document):
## 여기에 있던 Title ##
class Index:
name = 'book_all'
settings = {
'number_of_shards': 1,
'number_of_replicas': 0,
'max_ngram_diff': 20
}
class Django:
model = Book
fields = [
'Title',
'PublisherReview'
]## ~## 이 부분 지웠더니 해결
# search_app/search_indexes.py
from django_elasticsearch_dsl import Document, Index
from elasticsearch_dsl import analyzer, tokenizer
from .models import Book
# Elasticsearch DSL을 사용하여 인덱스 정의
book_all = Index('book_all')
combined_analyzer = analyzer('combined_analyzer',
tokenizer=tokenizer('ngram', 'nGram', min_gram=2, max_gram=20),
filter=['lowercase']
)
# 모델과 연결
@book_all.doc_type
class BookDocument(Document):
class Index:
name = 'book_all'
settings = {
'number_of_shards': 1,
'number_of_replicas': 0,
'max_ngram_diff': 20
}
class Django:
model = Book
fields = [
'Title',
'PublisherReview'
]
#search_app/setting_bulk.py
from elasticsearch import Elasticsearch
es = Elasticsearch() #파라미터 추가
# 'combined_analyzer' 분석기를 Elasticsearch에 추가
es.indices.put_settings(
index='book_all',
body={
"settings": {
"analysis": {
"tokenizer": {
"ngram_tokenizer": {
"type": "ngram",
"min_gram": 2,
"max_gram": 20
}
},
"analyzer": {
"combined_analyzer": {
"type": "custom",
"tokenizer": "ngram_tokenizer"
}
}
}
}
}
)
# 리인덱스 파이프라인 생성
es.ingest.put_pipeline(
id='reindex_pipeline',
body={
"description": "Reindexing pipeline with new analyzer",
"processors": [
{
"set": {
"field": "_source",
"value": {
"Title": "{{Title}}",
"PublisherReview": "{{PublisherReview}}"
# Add other fields as needed
}
}
}
]
}
)
# 리인덱스 파이프라인 실행
es.reindex(
body={
"source": {
"index": "book_all"
},
"dest": {
"index": "book_ngram",
"pipeline": "reindex_pipeline"
}
},
wait_for_completion=True,
request_timeout=300
)
# 분석기 정의 및 인덱스 생성
es.indices.create(
index='book_ngram',
body={
"settings": {
"analysis": {
"tokenizer": {
"nori_tokenizer": {
"type": "nori_tokenizer"
}
},
"filter": {
"ngram_filter": {
"type": "ngram",
"min_gram": 2,
"max_gram": 20
}
},
"analyzer": {
"combined_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer",
"filter": ["ngram_filter"]
}
}
}
},
"mappings": {
"properties": {
"Title": {
"type": "text",
"analyzer": "combined_analyzer"
},
"PublisherReview": {
"type": "text",
"analyzer": "combined_analyzer"
}
}
}
}
)이 코드로
Dev tools에서
GET /_cat/plugins?v
# 인덱스 닫기
POST /book_all/_close
# 인덱스 설정 변경
PUT /book_all/_settings
{
"settings": {
"index": {
"max_ngram_diff": 20
},
"analysis": {
"tokenizer": {
"ngram_tokenizer": {
"type": "ngram",
"min_gram": 2,
"max_gram": 20
}
},
"analyzer": {
"combined_analyzer": {
"type": "custom",
"tokenizer": "ngram_tokenizer"
}
}
}
}
}
# 인덱스 열기
POST /book_all/_open
GET /book_all/_settings
GET /book_all/_mapping이렇게 각각 쿼리 날렸는데
되는데,
여전히 ngram 적용 안됨!!
'엔드'를 검색했을 때 '백엔드', '프론트엔드' 들어간 것도 나와야되는데 안나옴!
from elasticsearch import Elasticsearch
es = Elasticsearch()
# 'combined_analyzer' 분석기를 Elasticsearch에 추가 (영어용)
es.indices.put_settings(
index='book_all',
body={
"settings": {
"analysis": {
"tokenizer": {
"ngram_tokenizer": {
"type": "ngram",
"min_gram": 2,
"max_gram": 20
}
},
"analyzer": {
"combined_analyzer": {
"type": "custom",
"tokenizer": "ngram_tokenizer"
}
}
}
}
}
)
# 'korean_analyzer' 분석기를 Elasticsearch에 추가 (한국어용)
es.indices.put_settings(
index='book_all',
body={
"settings": {
"analysis": {
"tokenizer": {
"nori_tokenizer": {
"type": "nori_tokenizer"
}
},
"filter": {
"ngram_filter": {
"type": "ngram",
"min_gram": 2,
"max_gram": 20
}
},
"analyzer": {
"korean_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer",
"filter": ["ngram_filter"]
}
}
}
}
}
)
# 리인덱스 파이프라인 생성
es.ingest.put_pipeline(
id='reindex_pipeline',
body={
"description": "Reindexing pipeline with new analyzer",
"processors": [
{
"set": {
"field": "_source",
"value": {
"Title": "{{Title}}",
"PublisherReview": "{{PublisherReview}}"
# Add other fields as needed
}
}
}
]
}
)
# 리인덱스 파이프라인 실행
response = es.reindex(
body={
"source": {
"index": "book_all"
},
"dest": {
"index": "book_ngram",
"pipeline": "reindex_pipeline"
}
},
wait_for_completion=True,
request_timeout=300
)
# 분석기 정의 및 인덱스 생성
es.indices.create(
index='book_ngram',
body={
"settings": {
"analysis": {
"tokenizer": {
"nori_tokenizer": {
"type": "nori_tokenizer"
}
},
"filter": {
"ngram_filter": {
"type": "ngram",
"min_gram": 2,
"max_gram": 20
}
},
"analyzer": {
"combined_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer",
"filter": ["ngram_filter"]
}
}
}
},
"mappings": {
"properties": {
"Title": {
"type": "text",
"analyzer": "combined_analyzer"
},
"PublisherReview": {
"type": "text",
"analyzer": "combined_analyzer"
}
}
}
}
)아니 ...
index랑 pipeline 문제인줄 알고
일단 reindexing할 book_ngram이랑 reindex_pipeline을 ES에 만들어놨는데,
내가 settings 적용해야할 book_all index에
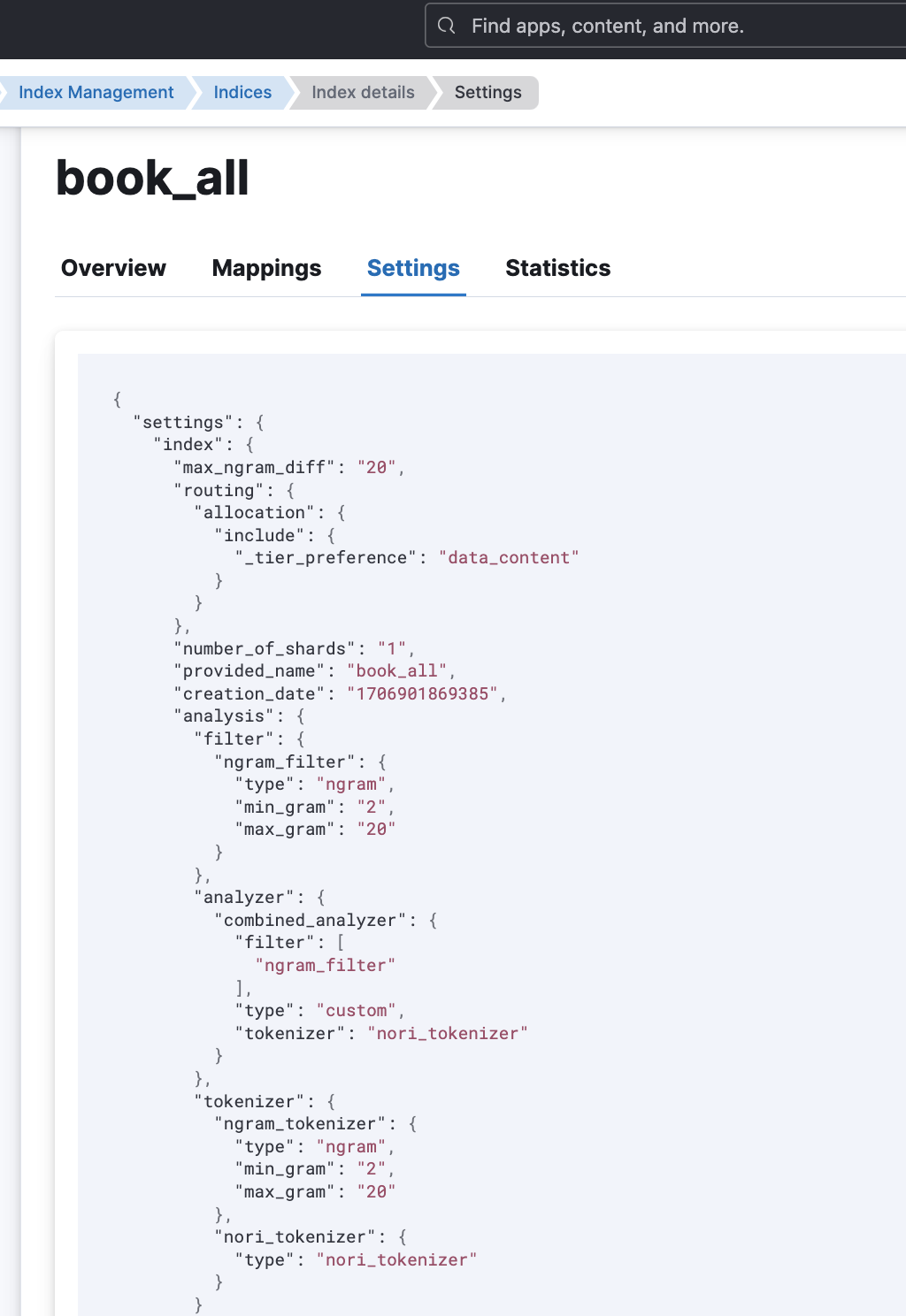
이전 코드에서 (korean - english 나누기 전)
ngram 설정한 settings가 들어가 있음...!!!!!
근데 문제가...
어떤 걸 설정해서 run했을 때 이게 적용된건지를 모름......
이걸 알면 수정이 될텐데 ...
오늘의 lesson learned... 쿼리를 날리거나 runserver할 때 내가 원하는 결과가 적용이 되는지 하나씩 꼼꼼히 확인하고 넘어갈 것...
근데 이걸 당연히
알지...
dev tools에서 쿼리 날린 결과만 보고 안됐다고 생각했는데 여기 세팅에는 적용된 걸 몰랐음
애당초에 이걸 볼 생각을 못했고 postman이랑 페이지에서만 날렸거든...
쿼리날리고 검색어 들어간 거 반환해주는 결과만 봤거든...
>> 근데 이거 django 파일 수정해서 된 게 아닌 것 같고,
PUT /book_all/_settings
{
"settings": {
"index": {
"max_ngram_diff": 20
},
"analysis": {
"tokenizer": {
"nori_tokenizer": {
"type": "nori_tokenizer"
}
},
"filter": {
"ngram_filter": {
"type": "ngram",
"min_gram": 2,
"max_gram": 20
}
},
"analyzer": {
"combined_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer",
"filter": ["ngram_filter"]
}
}
}
}
}dev tools에서 직접적으로 날려줘서 들어간 것 같다.
결론. 다시 ES랑 Django 연결 알아봐야된드아 ...
2/6
수정해봐야할 것
1. analyzer 코드
# 분석기 선택 함수 #### 코드 수정해야할 것 같음 ###
def combined_analyzer(language):
if language == 'english':
return analyzer(analyzer=combined_analyzer, tokenizer=tokenizer('ngram', 'nGram', min_gram=2, max_gram=20), filter=['lowercase'])
elif language == 'korean':
return analyzer('korean_analyzer', tokenizer='nori_tokenizer', filter=['ngram_filter'])
2. ngram 세팅 메핑 부분 코드
type / fields / filter 어떤것에 ngram 넣어야 할지
https://bbuljj.tistory.com/191
Python - Elastic Search Service [6.x] 생성, 조회, 삭제
Elastic Search를 사용해 인덱스 생성 / Mapping / 조회 / 삭제 방법에 대해 알아보겠습니다. * Enviroment - Python 3.6 - Django 1.11 - Auth : AWS4Auth - index : text_index - doc : _doc * 이 포스트에서 편의를 위해 ElasticSearc
bbuljj.tistory.com
https://soyoung-new-challenge.tistory.com/72
[Elasticsearch] python에서 엘라스틱 사용하기
이번 포스팅은 파이썬에서 엘라스틱을 연결해서 데이터를 insert, delete, search 등 다양한 요청을 하는 튜토리얼입니다. 필요한 라이브러리 설치 $ pip install elasticsearch - 파이썬에서 엘라스틱을 연결
soyoung-new-challenge.tistory.com
이건 book_all 인덱스 미리 매핑되어 있던 것
{
"mappings": {
"properties": {
"Author": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"DetialCategory": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"ISBN": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"ImageURL": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"IndexContent": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"Introduction": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"MiddleCategory": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"Price": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"PubDate": {
"type": "date"
},
"Publisher": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"PublisherReview": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"PurchaseURL": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"Title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
elasticsearch 실행
/bin 에서 ./elasticsearch 명령어
에러 날시 logs에서 elasticsearch.log 파일에서 확인 가능
BadRequestError at / BadRequestError(400, 'index_closed_exception', 'closed')
이 에러는 인덱스가 닫혀있어서 그렇다
키바나 화면에서
POST /book_all/_open이걸로 열어주면 된다
'프로젝트 > AWS winter camp - ELK&AWS 프로젝트' 카테고리의 다른 글
| [Figma - 노코드 툴 Anima plugin 연결] npm run dev 에러 해결 (1) | 2024.02.10 |
|---|---|
| Elasticsearch n-gram 최종 구현 (1) | 2024.02.09 |
| Elasticsearch, django - rest_framework로 검색엔진 만들기 - 3차 트러블슈팅(해결) (0) | 2024.02.03 |
| Elasticsearch NLP에 ChatGPT & streamlit에 n-gram 추가하기(실패) (1) | 2024.02.01 |
| Elasticsearch, django - rest_framework로 검색엔진 만들기 - 2차 트러블슈팅(미해결) (2) | 2024.02.01 |